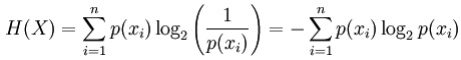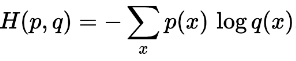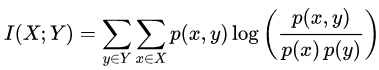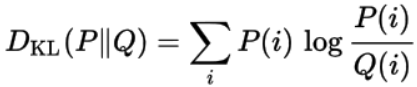Il fornitore cinese ZTE prevede che la connettività 3D, il MIMO intelligente, la topologia on-demand e l’intelligenza artificiale on-demand rappresenteranno gli abilitatori essenziali delle future reti 6G, ha dichiarato il portavoce dell’azienda Jason Tu a RCR Wireless News.
Il gruppo di ricerca 6G di ZTE ritiene inoltre che la radio intelligente, la copertura intelligente e l’evoluzione intelligente sarebbero le caratteristiche essenziali dell’architettura di rete 6G, ha affermato il dirigente.
“La missione 6G di ZTE è connettere il mondo fisico con il mondo digitale in modo intelligente. L’Internet della percezione, l’Internet dell’intelligenza artificiale e l’Internet dell’industria consentiranno nuovi servizi, che potrebbero nascere nell’era del 6G.
“ZTE è impegnata in lavori di ricerca completi sul traffico e sui requisiti 6G, sull’architettura di rete 6G e sui principali abilitatori 6G.
ZTE ha istituito uno specifico team 6G nel 2018 e creato cinque centri di innovazione congiunti con università cinesi di alto livello, concentrandosi sugli aspetti scientifici e ingegneristici fondamentali del 6G, tra cui l’architettura di rete 6G, il nuovo spettro, la nuova interfaccia aerea e l’integrazione con reti artificiali. intelligenza e blockchain, insieme a materiali e dispositivi di base all’avanguardia legati al 6G.
All’inizio di questo mese, ZTE e la compagnia connazionale China Unicom avevano raggiunto un accordo per lo sviluppo delle tecnologie 6G.
Basandosi sulla rete di China Unicom, entrambe le società esploreranno insieme le prospettive e le tendenze tecniche del 6G. Secondo l’industria, la commercializzazione della tecnologia 6G dovrebbe avvenire intorno al 2030.
Secondo i termini dell’accordo, ZTE e China Unicom coopereranno sull’innovazione tecnologica e sugli standard 6G promuovendo al tempo stesso attivamente l’integrazione approfondita del 6G con le reti satellitari, l’Internet delle cose (IoT), l’Internet dei veicoli e le tecnologie industriali. IoT.
Inoltre, le due parti condurranno una ricerca congiunta sulle potenziali tecnologie chiave del 6G, tra cui la connettività tridimensionale, la comunicazione terahertz e la comunicazione e rilevamento integrati. ZTE e China Unicom verificheranno inoltre la fattibilità di queste tecnologie attraverso sia test di verifica che prove di prototipazione per raggiungere gli obiettivi prestazionali della rete 6G, come la velocità dati di picco di 1 Tbps, la velocità dati sperimentata dall’utente di 20 Gbps e il volume capacità di traffico di 100Gbps/m3.
La Cina aveva ufficialmente iniziato la ricerca sulla tecnologia 6G nel novembre 2019, pochi giorni dopo che gli operatori di telecomunicazioni statali avevano lanciato le reti 5G nel paese.
Il Ministero della Scienza e della Tecnologia ha dichiarato che prevede di istituire due gruppi di lavoro per svolgere le attività di ricerca sul 6G.
Un gruppo sarà composto dai dipartimenti governativi competenti responsabili di promuovere le modalità con cui verranno svolte la ricerca e lo sviluppo del 6G. L’altro gruppo sarà composto da 37 università, istituti di ricerca e aziende, che si concentreranno esclusivamente sul lato tecnico delle tecnologie 6G.
Tuttavia, il governo cinese ritiene che ci sia ancora molta strada da fare prima che la tecnologia 6G possa essere definita. Il vice ministro Wang Xi del Ministero della Scienza e della Tecnologia ha dichiarato: “La fase iniziale e il percorso tecnico [del 6G] non sono ancora chiari, e gli indicatori chiave e gli scenari applicativi non sono stati standardizzati e definiti”.
La Cina non è l’unico paese a svolgere attivamente ricerche sulla tecnologia 6G. Paesi come il Giappone, la Corea e la Finlandia hanno tutti progetti di ricerca in corso sulla prossima generazione di tecnologia wireless.
Oggi sabato 25 gennaio è il 5G Global Protest Day. In tutto il mondo e anche in Italia, in diverse piazze, si protesta per far accendere i riflettori su questa tecnologia che sta per entrare nelle nostre vite, forse troppo avventatamente.
Lo Stato italiano ha già incassato 6,5 miliardi dalla vendita delle concessioni per l’uso delle frequenze 5G ai vari Vodafone, Tim, Iliad, ecc. e quindi non sembra molto intenzionato a fermare questo processo.
Perché ci sono persone che si vogliono opporre a questa tecnologia? Fondamentalmente perché non si trova rispettato il principio di precauzione: una tecnologia può essere introdotta quando è provato che sia innocua verso la salute delle persone e dell’ambiente. Nessuno può onestamente prevedere però quali possono essere gli effetti sulla salute di campi elettromagnetici, anche se di bassa intensità, ma presenti costantemente sull’organismo umano.
La tecnologia 5G infatti, garantendo una bassa latenza, vuole essere utilizzata per tutte quelle applicazioni come la guida autonoma, Internet delle cose, ecc. che devono funzionare di continuo. Insomma Internet non ci “lascerebbe mai”, o meglio, saremmo sempre “connessi”. Con il principio di precauzione, l’amianto non sarebbe mai stato introdotto e ora non staremmo a piangere tanti morti, né a spendere tanti soldi per rimuoverlo da ogni parte.
Chi spinge per questa tecnologia sostiene che non si possono mettere troppi freni a questo tipo di sviluppo, mentre i vantaggi sarebbero enormi per il genere umano.
Permettetemi un paragone con quello che può essere stato, nella storia dell’evoluzione dell’essere umano, il momento dell’introduzione della plastica: sicuramente un materiale fantastico, che ha permesso tantissime cose in maniera sicura ed economica sconvolgendo totalmente il nostro mondo. Ora però il nostro stesso mondo è invaso da questa invenzione così preziosa che fa fatica a sparire quando non ci serve più, tanto da entrare oramai addirittura nella nostra catena alimentare.
Lo sviluppo tecnologico è sicuramente utile, non possiamo che ringraziare per i progressi che abbiamo avuto nella medicina, nella possibilità di trasporti, nel rendere confortevoli le nostre case e più leggere le nostre fatiche, ma possiamo provare a pensare, almeno una volta, a cosa possono comportare le nostre scelte? Possiamo ammettere che siamo molto più stressati, distratti e nervosi da quando siamo “connessi”? Che questi mezzi (smartphone, tablet, ecc.) sviluppano sicuramente una forma di dipendenza? Siamo così sicuri che vogliamo andare nella direzione di essere ancora sempre più “connessi”? Non può essere che il sistema economico nel quale viviamo, perché non siamo riusciti a trovarne finora uno migliore, abbia per l’ennesima volta bisogno di crearci un bisogno per poi venderci la soluzione?
I sostenitori della tecnologia 5G dicono che sarà un passo in più verso la sostenibilità ambientale perché sarà richiesta molta meno energia per trasmettere un dato con onde elettromagnetiche. Peccato che aumenterà esponenzialmente la quantità di dati scambiati e il risultato della nostra sostenibilità potete immaginare come sarà: come le nostre auto moderne che inquinano e consumano molto di meno di quelle di 30 anni fa, ma abbiamo molti più problemi di inquinamento perché abbiamo più macchine e percorriamo molti più chilometri.
La teoria dell’informazione è un campo importante che ha dato un contributo significativo all’apprendimento profondo e all’IA, e tuttavia è sconosciuto a molti. La teoria dell’informazione può essere vista come una fusione sofisticata di elementi costitutivi fondamentali dell’apprendimento profondo: calcolo, probabilità e statistica. Alcuni esempi di concetti nell’intelligenza artificiale che provengono dalla teoria dell’informazione o dai campi correlati:
Popolare funzione di perdita di entropia incrociata
Costruire alberi decisionali sulla base del massimo guadagno di informazioni
Algoritmo di Viterbi ampiamente usato in NLP e Speech
Concetto di codificatore di encoder usato comunemente in RNN di traduzione automatica e vari altri tipi di modelli
Breve introduzione alla storia della teoria dell’informazione
Claude Shannon, il padre dell’età dell’informazione.
All’inizio del 20 ° secolo, scienziati e ingegneri erano alle prese con la domanda: “Come quantificare l’informazione? Esiste un modo analitico o una misura matematica che ci può dire del contenuto informativo? “. Ad esempio, considera sotto due frasi:
Bruno è un cane.
Bruno è un grosso cane marrone.
Non è difficile dire che la seconda frase ci dà più informazioni in quanto dice anche che Bruno è “grande” e “marrone” oltre ad essere un “cane”. Come possiamo quantificare la differenza tra due frasi? Possiamo avere una misura matematica che ci dice quante più informazioni hanno la seconda frase rispetto alla prima?
Gli scienziati stavano lottando con queste domande. Semantica, dominio e forma di dati aggiunti solo alla complessità del problema. Quindi, il matematico e ingegnere Claude Shannon ha avuto l’idea di “Entropia” che ha cambiato il nostro mondo per sempre e ha segnato l’inizio di “Digital Information Age”.
Shannon ha introdotto il termine “bit” nel 1948, che ha umilmente accreditato al suo collega John Tukey.
Shannon ha proposto che “gli aspetti semantici dei dati sono irrilevanti”, e la natura e il significato dei dati non hanno importanza quando si tratta di contenuto informativo. Invece ha quantificato le informazioni in termini di distribuzione di probabilità e “incertezza”. Shannon ha anche introdotto il termine “bit”, che ha umilmente accreditato al suo collega John Tukey. Questa idea rivoluzionaria non solo gettò le basi della Teoria dell’informazione, ma aprì anche nuove strade per il progresso in campi come l’intelligenza artificiale.
Di seguito discutiamo di quattro concetti teorici di informazione popolare, ampiamente utilizzati e da conoscere in ambito di deep learning e data science:
entropia
Chiamato anche Entropia di informazioni o Entropia di Shannon.
L’entropia è una misura di casualità o incertezza in un esperimento.
Intuizione
L’entropia fornisce una misura di incertezza in un esperimento. Consideriamo due esperimenti:
Lancia una moneta equa (P (H) = 0,5) e osserva la sua uscita, diciamo H
Lancia una moneta parziale (P (H) = 0,99) e osserva la sua uscita, diciamo H
Se confrontiamo i due esperimenti, nell’esp 2 è più facile predire l’esito rispetto all’esp. 1. Quindi, possiamo dire che exp 1 è intrinsecamente più incerto / imprevedibile di exp 2. Questa incertezza nell’esperimento viene misurata usando l’entropia .
Pertanto, se c’è maggiore incertezza inerente nell’esperimento, allora ha un’entropia più alta. O meno l’esperimento è prevedibile, più è l’entropia. La distribuzione di probabilità dell’esperimento viene utilizzata per calcolare l’entropia.
Un esperimento deterministico, che è completamente prevedibile, diciamo che lanciare una moneta con P (H) = 1, ha entropia zero. Un esperimento che è completamente casuale, dice rolling fair dado, è meno prevedibile, ha massima incertezza e ha l’entropia più alta tra tali esperimenti.
L’esperimento di lanciare una moneta equa ha più entropia che lanciare una moneta parziale.
Un altro modo di guardare l’entropia è l’informazione media acquisita quando osserviamo i risultati di un esperimento casuale. Le informazioni acquisite per un risultato di un esperimento sono definite come una funzione della probabilità di accadimento di quel risultato. Più il più raro è il risultato, più è l’informazione acquisita dall’osservarla.
Ad esempio, in un esperimento deterministico, conosciamo sempre il risultato, quindi nessuna nuova informazione acquisita è qui dall’osservazione del risultato e quindi l’entropia è zero.
Matematica
Per una variabile casuale discreta X , con possibili risultati (stati) x_1, …, x_n l’entropia, in unità di bit, è definita come:
dove p (x_i) è la probabilità di I ^ esimo risultato di X .
Applicazione
L’entropia viene utilizzata per la costruzione automatica di alberi decisionali. In ogni fase della costruzione di un albero, la selezione delle funzioni viene effettuata utilizzando i criteri di entropia.
La selezione del modello basata sul principio dell’entropia massima, che stabilisce dai modelli in competizione uno con l’entropia più alta è il migliore.
Cross-Entropy
Intuizione
L’entropia trasversale viene utilizzata per confrontare due distribuzioni di probabilità. Ci dice quanto siano simili due distribuzioni.
Matematica
L’entropia incrociata tra due distribuzioni di probabilità p e q definite sullo stesso insieme di risultati è data da:
Applicazione
I classificatori basati sulla rete neurale convoluzionale spesso usano il layer softmax come strato finale che viene addestrato usando una funzione di perdita di entropia incrociata.
La funzione di perdita di entropia incrociata è ampiamente utilizzata per i modelli di classificazione come la regressione logistica. La funzione di perdita di entropia incrociata aumenta man mano che le previsioni divergono dalle uscite reali.
Nelle architetture di apprendimento profondo come le reti neurali convoluzionali, lo strato finale di “softmax” utilizza frequentemente una funzione di perdita di entropia incrociata.
Informazioni reciproche
Intuizione
L’informazione reciproca è una misura della dipendenza reciproca tra due distribuzioni di probabilità o variabili casuali. Ci dice quante informazioni su una variabile sono trasportate dall’altra variabile.
L’informazione reciproca cattura la dipendenza tra variabili casuali ed è più generalizzata del coefficiente di correlazione della vaniglia, che cattura solo la relazione lineare.
Matematica
Le informazioni mutue di due variabili casuali discrete X e Y sono definite come:
dove p (x, y) è la distribuzione di probabilità congiunta di X e Y , e p (x) e p (y)sono la distribuzione di probabilità marginale di X e Y rispettivamente.
Applicazione
In una rete bayesiana, la struttura delle relazioni tra le variabili può essere determinata utilizzando l’informazione reciproca.
Selezione delle funzionalità: anziché utilizzare la correlazione, è possibile utilizzare le informazioni reciproche. La correlazione acquisisce solo le dipendenze lineari e perde le dipendenze non lineari ma le informazioni reciproche no. L’indipendenza reciproca di zero garantisce che le variabili casuali siano indipendenti, ma la correlazione zero no.
Nelle reti bayesiane, l’informazione reciproca viene utilizzata per apprendere la struttura delle relazioni tra variabili casuali e definire la forza di queste relazioni.
Kullback Leibler (KL) Divergenza
Chiamato anche Entropia relativa.
La divergenza KL è usata per confrontare due distribuzioni di probabilità
Intuizione
La divergenza di KL è un’altra misura per trovare somiglianze tra due distribuzioni di probabilità. Misura quanto una distribuzione diverge dall’altra.
Supponiamo, abbiamo alcuni dati e una vera distribuzione sottostante è “P”. Ma non conosciamo questa ‘P’, quindi scegliamo una nuova distribuzione ‘Q’ per approssimare questi dati. Dato che “Q” è solo un’approssimazione, non sarà in grado di approssimare i dati come “P” e si verificherà una perdita di informazioni. Questa perdita di informazioni è data dalla divergenza di KL.
La divergenza KL tra ‘P’ e ‘Q’ ci dice quante informazioni perdiamo quando proviamo ad approssimare i dati dati da ‘P’ con ‘Q’.
Matematica
La divergenza KL di una distribuzione di probabilità Q da un’altra distribuzione di probabilità P è definita come:
Applicazione
La divergenza KL è comunemente usata in autoincodenziatori a variazione continua non presidiata.
Information Theory è stato originariamente formulato dal matematico e ingegnere elettrico Claude Shannon nel suo seminario “A Mathematical Theory of Communication” nel 1948.
Nota: gli esperimenti sui termini, la variabile casuale e l’intelligenza artificiale, l’apprendimento automatico, l’apprendimento approfondito, la scienza dei dati sono stati usati in modo approssimativo ma hanno significati tecnicamente diversi.
Se ti è piaciuto l’articolo, seguimi Abhishek Parbhakar per altri articoli relativi a AI, filosofia ed economia.
Il termine intelligenza artificiale potrebbe far pensare a macchine dotate di vera conoscenza, in grado di ragionare e consapevoli di ciò che stanno facendo; le cose, invece, sono molto diverse: il fatto che un software impari a riconoscere se in una foto sono presenti dei gatti non significa che sappia che cosa sia un gatto; allo stesso modo, il computer che ha battuto Lee Sedol, il maestro di Go, non aveva la più pallida idea di che cosa stesse facendo (e lo stesso vale per lo storico esempio riguardante le partite a scacchi tra Deep Blue di IBM e Gary Kasparov).
Questi software, insomma, non sono in grado di pensare; sono semplicemente capaci di processare una quantità tale di dati da riuscire a metterli in relazione tra loro, identificando collegamenti e differenze in un paniere di dati o calcolando statisticamente, per esempio, quale mossa di un determinato gioco ha la maggior probabilità di avere successo.
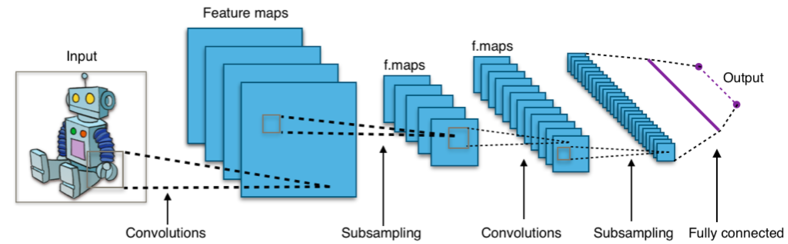
I metodi utilizzati per ottenere questi risultati sono principalmente due: il machine learning (apprendimento automatico) e la sua più recente evoluzione, il deep learning (apprendimento approfondito), un sistema dalle enormi potenzialità che si basa sugli stessi princìpi ma che, a differenza del machine learning, lavora su numerosi strati di “reti neurali” che simulano il funzionamento del cervello, organizzando l’analisi dei dati su diversi livelli e raggiungendo così una maggiore capacità di astrazione.
Le origini di questa branca dell’intelligenza artificiale risalgono agli anni ’50 e al lavoro di scienziati come Marvin Minsky, Frank Rosenblatt, Seymour Papert e Arthur Samuel (quest’ultimo ha coniato una importante definizione di machine learning: “una branca dell’intelligenza artificiale che fornisce ai computer l’abilità di apprendere senza essere stati esplicitamente programmati”). Per decenni, però, il fatto che questa tecnica non consentisse di raggiungere una vera e propria intelligenza artificiale, ma solo una sorta di calcolo statistico estremamente evoluto, le ha impedito di ottenere grande popolarità nel mondo accademico.
Nel caso del machine learning, la macchina scopre da sola come portare a termine un compito che le è stato dato
L’atteggiamento generale ha iniziato a cambiare solo negli anni ’90, quando è diventato evidente come il machine learning consentisse di risolvere parecchi problemi di natura pratica; il salto di qualità che l’ha infine imposto come strada maestra nel mondo della AI è avvenuto più recentemente, grazie alla crescente potenza di calcolo dei computer e a una mole senza precedenti di dati a disposizione, che ne hanno aumentato esponenzialmente le potenzialità.
Alla base di questa tecnica, c’è l’utilizzo di algoritmi che analizzano enormi quantità di dati, imparano da essi e poi traggono delle conclusioni o fanno delle previsioni. Per questo, nella definizione di Arthur Samuel, si parla di “abilità di apprendere senza essere stati esplicitamente programmati”: a differenza dei software tradizionali, che si basano su un codice scritto che spiega loro passo dopo passo cosa devono fare, nel caso del machine learning la macchina scopre da sola come portare a termine l’obiettivo che le è stato dato.
Un software che deve imparare a riconoscere un numero scritto a mano, per esempio il 5, viene quindi sottoposto a centinaia di migliaia di immagini di numeri scritti a mano, in cui è segnalato solo se sono dei 5 oppure non lo sono. A furia di analizzare numeri che sono o non sono dei 5, la macchina impara a un certo punto a riconoscerli, fornendo una percentuale di risposte corrette estremamente elevata. Da qui a essere davvero intelligenti, ovviamente, ce ne passa: basti pensare che, per imparare a riconoscere un certo numero, un’intelligenza artificiale deve essere sottoposta a migliaia e migliaia di esempi; a un bambino di quattro anni basta vederne cinque o sei.
Lo stesso metodo probabilistico è alla base di una quantità di operazioni che quotidianamente ci semplificano la vita: il machine learning viene impiegato dai filtri anti-spam per eliminare la posta indesiderata prima ancora che arrivi nelle nostre caselle, per consentire a Siri di capire (più o meno) che cosa le stiamo dicendo e a Facebook per indovinare quali tra i nostri amici sono presenti nelle foto; permette ad Amazon e Netflix di suggerirci quali libri o film potrebbero piacerci, a Spotify di classificare correttamente le canzoni in base al loro genere musicale. Già oggi, insomma, utilizziamo quotidianamente l’intelligenza artificiale, spesso senza nemmeno rendercene conto.
Per l’Oms è cancerogeno ma l’Ue potrebbe rinnovare l’autorizzazione. Malgrado l’allarme lanciato da Parigi
ELENA DUSI, la Repubblica • 26 Feb 16
Perfino la Colombia, a maggio del 2015, ha smesso di usarlo per distruggere le piantagioni di coca. L’Oms, il 20 marzo, aveva infatti classificato il glifosato – l’erbicida più diffuso al mondo – come «probabilmente cancerogeno per l’uomo». A smentirla, almeno parzialmente, era arrivata il 12 novembre del 2015 l’Efsa, l’Autorità europea per la sicurezza alimentare di Parma: «È poco probabile che la sostanza sia tossica per il Dna o aumenti il rischio di cancro negli uomini».
Tossico o no, il glifosato è sicuramente un argomento scivoloso. E la Commissione Europea – chiamata nei prossimi giorni a rinnovare il permesso per l’utilizzo dell’erbicida nel territorio dell’Ue per altri 15 anni – è già entrata nel mirino delle associazioni di cittadini. Trentadue gruppi ambientalisti italiani, riuniti nel movimento “Stop glifosato”, due giorni fa hanno scritto al governo chiedendogli di schierarsi per il divieto. Contro il rinnovo dell’autorizzazione al diserbante si è espressa, dieci giorni fa, anche il ministro dell’ambiente francese Ségolène Royal, che ha chiesto all’Agenzia di sicurezza sanitaria di Parigi di vietare il glifosato se mescolato con altre sostanze chimiche ”adiuvanti”: in particolare le tallowamine, già vietate anche in Germania.
La Commissione, che sarà chiamata a prendere la sua decisione fra il 7 e l’8 marzo, sembra in effetti orientata ad autorizzare il glifosato purché non in combinazione con le tallowamine. Sulla decisione di Bruxelles potrebbe però pesare la notizia del ritrovamento di alcune tracce dell’erbicida nelle 14 marche di birra tedesche più vendute, secondo un’analisi commissionata dal gruppo ambientalista “Munich Environmental Institute”. Le quantità riscontrate, secondo l’associazione tedesca, supererebbero il limite di 0,1 microgrammi per litro previsto per l’acqua potabile, anche se l’Istituto federale tedesco per la determinazione del rischio ha escluso possibili effetti sulla salute. In Francia minime quantità di glifosato sono state rintracciate anche in una marca biologica di assorbenti femminili.
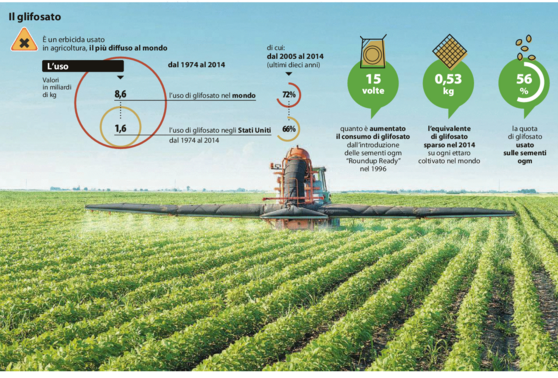
Il glifosato, secondo una ricerca pubblicata su Environmental Sciences il primo febbraio, è l’erbicida più diffuso al mondo, con 8,6 miliardi di chilogrammi spruzzati nel 2014. La sostanza è usata, tra gli altri, dalla Monsanto per il suo “Roundup”, il diserbante associato alle sementi geneticamente modificate “Roundup Ready”. Ed è proprio a partire dall’introduzione delle coltivazioni ogm, nel 1996, che il prodotto ha registrato un boom di consumo. La ricerca di Environmental Sciences fa notare che due terzi del glifosato usato nei campi statunitensi sono stati spruzzati negli ultimi dieci anni. A gennaio 2016, riferisce la Reuters, la Monsanto ha fatto causa allo stato della California che aveva proposto di inserire il glifosato nella sua lista delle sostanze cancerogene.
Il glifosate fu brevettato come erbicida dalla Monsanto Company nel 1974, multinazionale specializzata in biotecnologie agrarie, sementi e leader mondiale nella produzione di alimenti Ogm; agisce bloccando nutrienti minerali essenziali per la vita di piante, microorganismi e animali e, anche se era stato presentato come una sostanza rapidamente biodegradabile e non tossica, è invece ampiamente diffuso nell’ambiente insieme al suo metabolita Ampa. Il glifosate altera gli ecosistemi con cui entra in contatto e compromette la stabilità dei terreni, riduce la biodiversità e contribuisce in modo determinante al dissesto idrogeologico: la sempre più frequente franosità in coincidenza di eventi metereologici è anche conseguenza della carente azione di assorbimento da parte della cotica erbosa – distrutta dall’erbicida – e della lisciviazione del terreno. Glifosate ed Ampa sono le sostanze maggiormente presenti nelle acque italiane, come segnala il rapporto Ispra e purtroppo ricercate sistematicamente solo in Lombardia. Di recente anche in Toscana è stata ricercata questa sostanza su un centinaio di campioni di acque destinate al consumo umano ed è emerso che; “l’erbicida glifosate, per quanto ricercato in un numero limitato di campioni a causa della complessità del metodo di analisi, è stato rilevato in una percentuale elevata di analisi, anche superiori a 1 microgrammo/litro”.
RAI.IT NEWS AGRICOLTURA
UE, RINVIATA DECISIONE SUL GLIFOSATO. DUBBI SUI RISCHI PER LA SALUTE Lo slittamento della decisione sul rinnovo dell’autorizzazione al commercio dell’erbicida più venduto al mondo è arrivato dopo le pressioni di Italia, Francia, Ong e gruppi dell’Europarlamento Tweet Erbicida (gettyimages) Agricoltura, a rischio tutte le coltivazioni Agricoltura europea minacciata dal riscaldamento climatico Ogm, Parlamento Ue approva norma sulla libera scelta degli Stati Coltivare Ogm è ancora vietato, respinto un ricorso al Consiglio di Stato 09 marzo 2016 La Commissione Europea non ha ancora preso una decisione sull’autorizzazione alla vendita del glifosato, l’erbicida più usato al mondo. Nonostante quattro anni di studi e 90mila pagine di documenti, la Commissione ha rinviato la scelta. Uno slittamento dovuto ai dubbi sulla sicurezza per la salute. Ci sono pareri discordanti sul rischio di cancerogenicità dell’erbicida: per l’autorità Ue per la sicurezza alimentare (Efsa) “è improbabile che sia cancerogeno” mentre per l’Oms (Organizzazione mondiale della Sanità) è “probabilmente cancerogeno”. Bruxelles non intende rinunciare a una decisione entro giugno quando scadrà l’autorizzazione in corso: ha chiesto così agli esperti dei 28 stati UE di inviarle per il 18 marzo le proposte di modifica che auspicano siano apportate al testo in discussione. La questione sarà di nuovo sul tavolo del prossimo comitato europeo in programma il 18 e 19 maggio, ma la riunione potrebbe essere anticipata. Il no al glifosato è sostenuto dall’Italia, dalla Francia e dall’Olanda, ma anche da diversi gruppi politici del Parlamento europeo, dai Socialdemocratici ai Verdi, fino alle Ong. La Germania e altri Stati hanno detto che in caso di voto si sarebbero astenuti. Il ministro per le Politiche Agricole, Maurizio Martina, quello della Salute, Beatrice Lorenzin, e il ministro dell’Ambiente, Gian Luca Galletti, sono d’accordo sul superamento dell’utilizzo del glifosato. “Ancora prima della discussione europea sul glifosato abbiamo iniziato un lavoro coordinato con le Regioni per incentivare pratiche agronomiche più sostenibili – ha commentato Martina in un’intervista a Repubblica – Nella scelta degli obiettivi prioritari di spesa dei fondi europei, infatti, abbiamo destinato oltre 2 miliardi alla produzione integrata che ci consentirà anche di percorrere la strada dell’azzeramento dell’uso del glifosato entro il 2020”. Sul glifosato l’Italia non ha “nessuna posizione ideologica – aggiunge il ministro – il glifosato è un prodotto utilizzato in tutta Europa e per questo serve una decisione comune che non penalizzi nessun singolo Paese. Noi lavoriamo per un suo superamento. In generale, negli ultimi 10 anni l’uso di pesticidi in italia si è ridotto del 45%. Il segno che i nostri agricoltori hanno già iniziato a fare scelte precise”. Le organizzazioni agricole hanno messo le mani avanti: “In una situazione di forti importazioni low cost – ha detto Coldiretti – è necessario che l’eventuale divieto riguardi coerentemente anche l’ingresso in Italia e nell’Ue di prodotti stranieri con residui di glifosato”. Confagricoltura ha invitato alla prudenza. “Prima di togliere l’autorizzazione ad un erbicida come il glifosato servono certezze scientifiche, altrimenti si crea solo un danno ai produttori e all’ambiente”. – See more at: http://www.rainews.it/dl/rainews/articoli/Ue-Rinviata-decisione-sul-glifosato-Dubbi-sui-rischi-per-la-salute-b1ad2220-f8a2-417e-bbc5-f38b2960eb97.html